The memory model for a multithreaded system specifies how memory actions (reads and writes) will appear to execute to the programmer. It specifically focuses on which value each read of a memory location may return.
The model was revised as JSR-133 and took effect in Java 5.0.
Why do we need a Memory Model?
It is difficult for programmers to reason about specific hardware memory architecture, processor optimizations and JIT compiler optimizations. For ease of use, Java Memory Model, therefore specifies high level portable Java programming constructs and design guidelines so that programmers do not have to reason about underlying hardware or runtime JIT compiler details.
Variable Visibility Problem
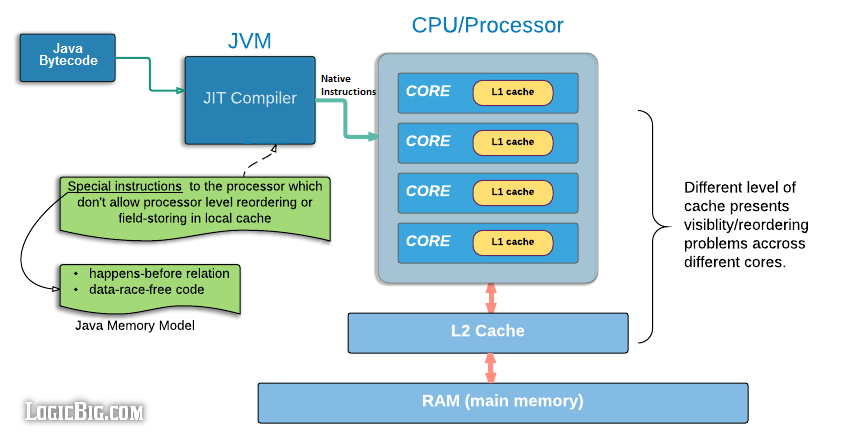
In multi-processor/multi-core environment there might be multiple level of memory cache which improves performance by speeding up data access. But this type of processor architecture presents visibility problem of the shared variable across multiple threads. Special processor level instructions are required to flush or invalidate the local processor/core cache in order to see writes made by other thread or make writes by this threads visible to others.
Code reordering Problem
Java environment allows code optimizations. These optimizations may be performed by JIT compiler (depending on JVM implementation) or by javac. These optimizations are embedded in the low level hardware processor. JIT must input some special instructions to the processor to control the optimizations to avoid unwanted results. Also not all processors offer some sort of standard optimizations. These optimizations differ from processors to processors.
The optimizations might be involved in reordering of the programmer's code. These optimization are usually done in such a manner which do not effect the single thread overall result. In addition, the memory hierarchy of the processor architecture on which a JVM is running may make it appear as if code is being reordered. If multiple threads are performing reads/writes actions to some shared data the result of such optimization might produce behavior that seem paradoxical to the programmer.
Sequential Consistency
Java memory model could be based on sequential consistency which allows a single order in which the memory actions happen in a sequence, regardless of what processor/core they execute on, and that each read of a variable will see the last write in the execution order to that variable by any processor.
Sequential consistency is a very strong guarantee that is made about visibility and ordering in an execution of a program. Within a sequentially consistent execution, there is a total order of over all individual actions (such as reads and writes) which is consistent with the order of the program. Each individual action is atomic and is immediately visible to every thread.
If sequential consistency was the memory model for Java environment then compiler and processor optimizations will not be possible. All modern shared memory multiprocessors offer optimization. Using sequential consistency as memory model would mean Java had to sacrifice processor level optimization.
`
So what is Java Memory Model?
According to Java Memory Model specs:
A program must be correctly synchronized to avoid reordering and visibility problems.
A program is correctly synchronized if:
- Actions are ordered by happens-before relationship.
- Has no data races. Data races can be avoided by using Intrinsic Locks.
What is data race?
When a program contains two conflicting accesses that are not ordered by a happens-before relationship, it is said to contain a data race.
What is conflicting access?
Two actions using the same shared field or array variable are said to be conflicting if at least one of the accesses is a write.
Synchronized blocks
Intrinsic synchronized blocks accomplish two things:
- Mutual exclusion of the shared blocked-code between two or more threads. That means they achieve atomicity of composite actions within the block with regards to multiple thread access.
- Locking and unlocking actions causes flushing of local processor cache for a thread, so that fixes visibility problems.
The volatile Keyword
Declaring shared variables as volatile ensures visibility. Use of volatile is insufficient for cases where the atomicity of composite or multiple actions must be guaranteed. Using volatile doesn't necessarily fix the problem of reordering. For composition actions we should use Intrinsic Locks which guarantees no-reordering and visibility problem.
Declaring variables as volatile establishes a happens-before relationship such that a write to a volatile variable is always seen by subsequent reads of the same variable in other threads.
Final Fields
Fields declared final are initialized once, but never changed under normal circumstances.
JIT Compiler has a great deal of freedom to move reads of final fields across synchronization blocks without actually reading it from main memory
There's no visibility problems with final fields. The processors/cores don't necessarily need to flush/invalidate the local cache for them.
JIT compilers are allowed to keep the value of a final field cached in a register and not reload it from memory in situations where a non-final field would have to be reloaded.
Final fields also allow programmers to implement thread-safe immutable objects without synchronization. A thread-safe immutable object is seen as immutable by all threads, even if a data race is used to pass references to the immutable object between threads.
A field cannot be
final and
volatile at the same time, doing so is a compile time error.
In next tutorials we will see some examples to produce problems mentioned above along with memory model solutions.
|
